The Problem Nobody Wanted to Quantify
Motor insurance claim fraud is not a fringe problem. It sits at the centre of every insurer's cost structure, quietly inflating premiums and eroding margins - yet most insurers in 2019 were still validating claims the same way they had in 1999: a field agent drives to the location, photographs the vehicle, and a desk adjuster manually reviews the photos against the claim narrative.
The process was slow, expensive, and deeply inconsistent. Two adjusters looking at the same photo could reach different conclusions about whether a bumper needed repair or replacement. A claimant could photograph a vehicle at a location entirely different from where the incident was reported, and nobody would know. The ground agents were stretched thin, costs per claim assessment were high, and the backlog of pending validations was a permanent fixture of operations.
When a leading insurance company in India approached us, they were not looking for incremental improvement. They wanted to understand whether AI could automate the first layer of claim review entirely, removing human judgment from the initial validation and reserving adjuster time for genuinely complex or escalated cases.
I led the full engagement: client discovery, solution architecture, dataset construction, model training, and delivery of the working proof of concept.
Why 2019 Made This Hard
It is worth pausing here, because the technical context matters enormously.
In 2025, you could build a reasonable version of this system in an afternoon. You would feed vehicle photos into a multimodal LLM, describe what you need in a prompt, and receive structured output. The hard part would be the business logic, not the AI.
In 2019, none of that existed. GPT-3 was still a year away. Multimodal models were a research concept. What we had was Azure Computer Vision for general image analysis, and Azure Custom Vision for training custom classification models on domain-specific data.
This meant we could not simply ask a model to "look at this car and tell me what is damaged." We had to teach the model what damage looked like - from scratch, on our own data, with our own labels.
That distinction shaped every decision we made.
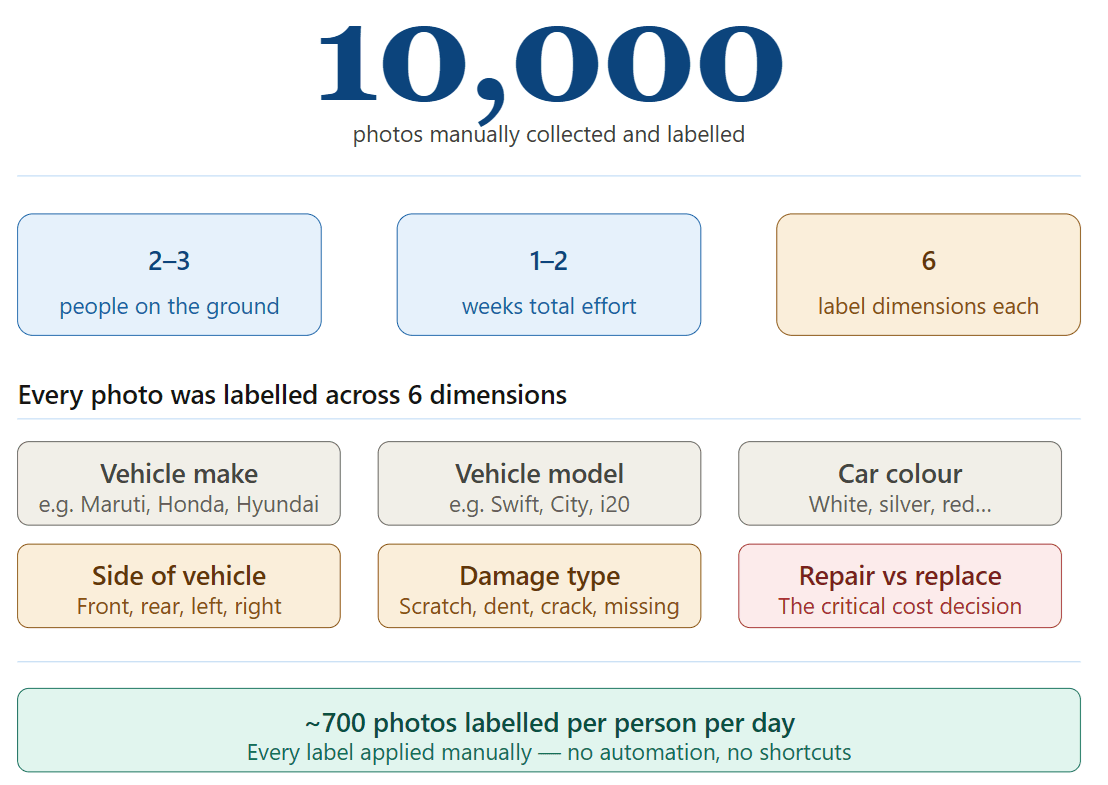
Building the Dataset: 10,000 Photos from Chennai
The first and in many ways the most important, problem was data.
Insurance companies hold large volumes of claim photos, but those photos come with significant privacy and sensitivity constraints. A claim photo is not just an image of a car. It is evidence in a potential legal or financial dispute. It contains location metadata, timestamps, and vehicle identifiers. Getting access to that data for model training purposes requires agreements that most insurers are not set up to grant, particularly to an external vendor working on a POC.
We solved this by going directly to the source.
With proper approvals in place, we visited car service centres in Chennai and systematically photographed vehicles across a wide range of makes, models, damage types, and conditions. We documented everything: the vehicle make and model, the specific panel or component visible in each photo, the nature of the damage (scratch, dent, crack, missing part), and whether the damage in our judgment warranted repair or full replacement.
By the time we had finished, we had approximately 10,000 labelled images. Every label was applied manually. Every classification decision, repair vs replace, damage severity, affected part, was made by a human and recorded.
This was painstaking work. It was also the foundation that made everything else possible.
How the System Worked
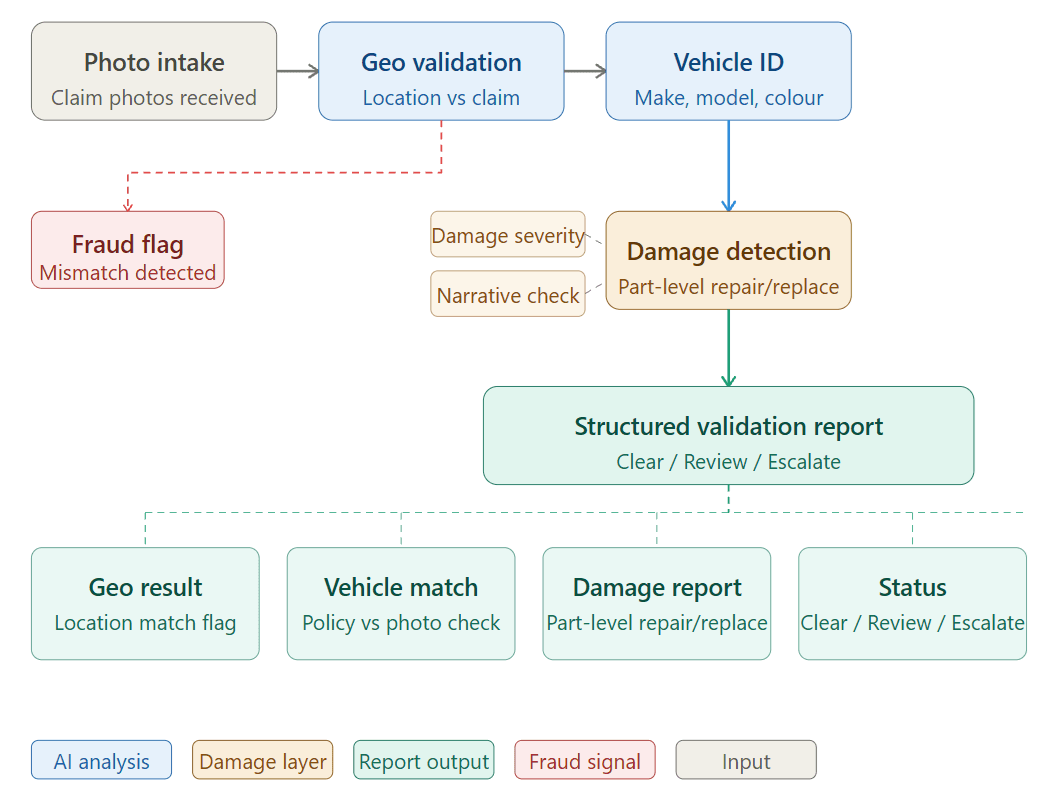
Once trained, the system processed incoming motor claims through a structured five-stage pipeline.
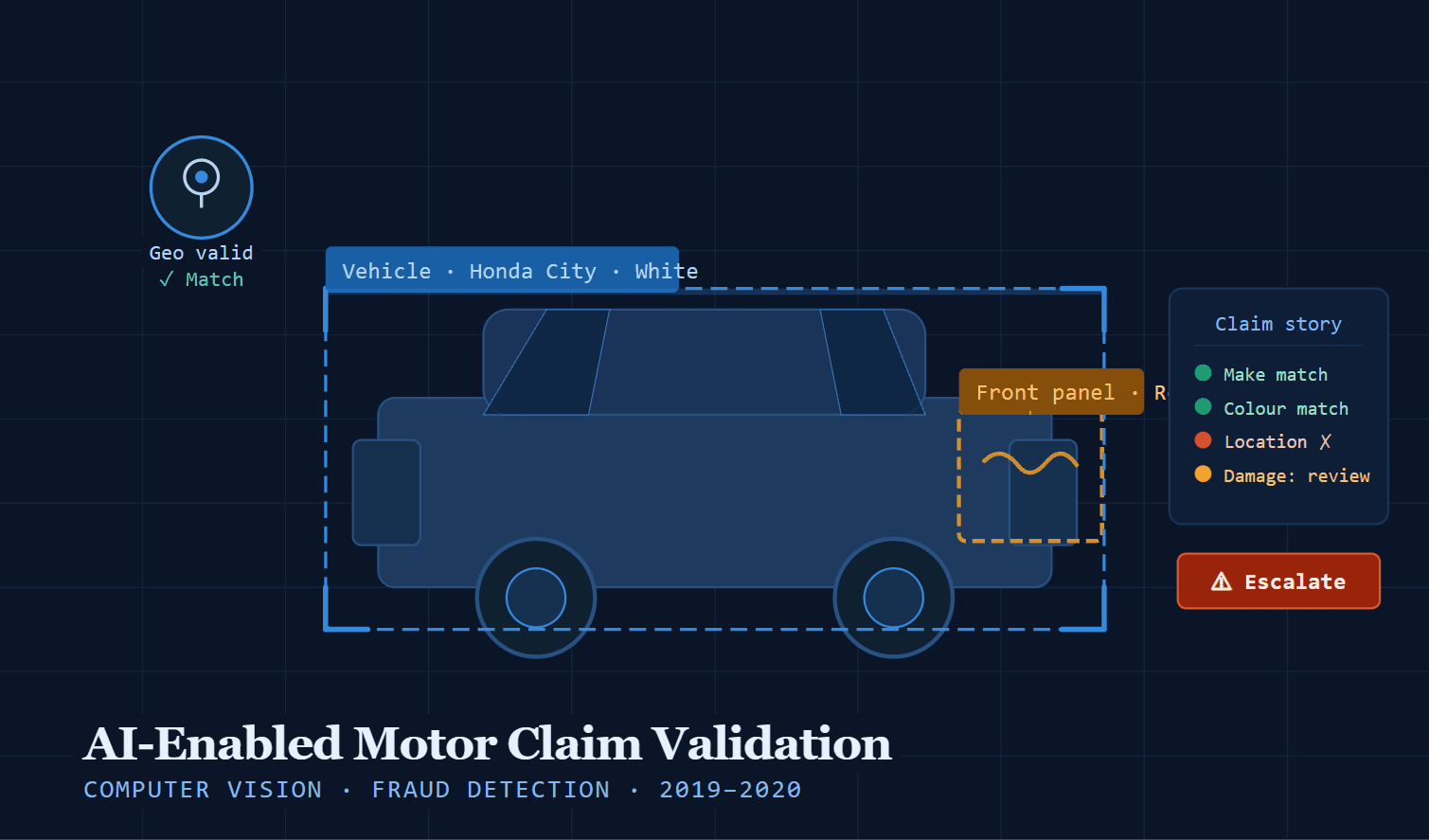
Stage 1 : Photo Intake & Geo-Validation
When a claimant submitted photos, the system extracted the EXIF metadata from each image, including GPS coordinates and timestamp. These were cross-referenced against the location and time of the reported incident. A claim stating that an accident occurred in South Mumbai, but with photos taken in Pune three days later, would immediately surface as a discrepancy requiring review.
This single feature which cost almost nothing to implement once the pipeline was in place turned out to be one of the most powerful fraud signals in the entire system.
Stage 2 : Vehicle Identification
Azure Computer Vision analysed each photo to identify the vehicle make, model, and colour. This was cross-referenced against the policy details submitted with the claim. A mismatch between the insured vehicle and the photographed vehicle was flagged automatically.
Stage 3 : Damage Detection & Part-Level Classification
Our Custom Vision model trained on the Chennai dataset, identified which parts of the vehicle were visible in each photo and assessed the damage present. For each affected part, the system produced a classification: no damage, minor damage (repair), or significant damage (replace).
This part-level granularity was deliberate. Insurance margins on motor claims are extremely sensitive to the repair-vs-replace decision. A bumper that gets classified as "replace" instead of "repair" can mean a difference of ₹8,000–₹15,000 on a single claim. At scale, across thousands of claims per month, that distinction is where a significant portion of cost and fraud lives.
Stage 4 : Narrative Cross-Referencing
The claim form submitted by the customer included a written description of the incident: what happened, where, how the vehicle was damaged. The system extracted key claims from this narrative and compared them against the photographic evidence.
If a customer described a rear-end collision but the photos showed damage only to the front left panel, that inconsistency was flagged. If the described damage severity was "minor scratch" but the photos showed a cracked chassis component, that was escalated.
Stage 5 : Structured Validation Report
The output was not a score or a single flag. It was a structured report covering: geo-validation result, vehicle identity match, part-level damage assessment with repair/replace recommendation for each component, narrative consistency check, and an overall validation status clear, review required, or escalate.
A claim adjuster receiving this report no longer needed to look at raw photos and make judgment calls from scratch. The system had done the initial analysis. Their job was to review the flagged exceptions and make final decisions on edge cases.
The Hardest Technical Challenges
Training data quality over quantity. 10,000 images sounds like a lot. For a general image classifier, it is reasonable. For a model that needs to distinguish a repairable dent on a Toyota Innova's rear quarter panel from a replacement-level dent on the same panel, it is not generous. We spent significant time on labelling consistency establishing clear criteria for what constituted each damage category, because model performance was only as good as the consistency of the labels it learned from.
Handling photo quality in the real world. Service centre photos were taken in controlled conditions. Real claim photos are taken in parking lots, on roadsides, in poor lighting, at unusual angles, sometimes deliberately obscured. We had to build robustness into the pipeline to handle low-quality inputs gracefully either extracting what signal was available or flagging the photo as insufficient for automated review.
Defining repair vs replace thresholds. This was not a technical problem. It was a business problem that required technical encoding. We worked closely with the client's claims team to establish the criteria which damage patterns, on which components, crossed the threshold from repair to replace. Getting alignment on these criteria was harder than building the model.
The geo-tagging edge cases. Not every phone embeds GPS data in photo EXIF. Some claimants submitted photos taken with devices that had location services disabled. We had to build logic that distinguished "no GPS data cannot validate" from "GPS data present location mismatch detected" without treating the former as suspicious by default.
What the POC Demonstrated
The proof of concept worked. It successfully:
- Identified vehicle make, model, and colour from photos with high confidence across the range of vehicles in our test set
- Detected damage at the part level and produced consistent repair/replace recommendations
- Flagged geo-location inconsistencies between photo metadata and claim location
- Cross-referenced claim narratives against photographic evidence and surfaced contradictions
- Generated structured validation reports that materially reduced the work required from human adjusters
The reduction in per-claim assessment workload was significant. Ground agents who had previously driven to every claim location for initial validation could be reserved for cases the system flagged as requiring physical inspection. The cost implication of that reallocation alone even without counting fraud prevention was the primary commercial driver.
Why It Did Not Go to Production And What That Actually Means
The POC did not convert into a production deployment. The reason is worth understanding clearly, because it is not a failure story.
The repair-versus-replace classification sits at the intersection of two sensitive domains: insurance liability and garage margins. An insurer's decision on whether to repair or replace a component directly affects what they pay out and indirectly signals what their internal cost benchmarks are for each part. That data, in aggregate, is competitively sensitive in ways that go beyond normal data privacy concerns.
After a successful POC, the client decided they wanted to develop this capability internally. They did not want an external vendor however trusted holding a trained model that had learned from their claims data and their adjuster decisions. The IP and the data sensitivity were too closely linked.
From a business perspective, this is a completely rational decision. From an engagement perspective, it is actually a strong outcome: the POC was compelling enough that the client wanted to own it. That is not rejection it is validation.
What I Would Do Differently Today
Building this in 2025 would look substantially different.
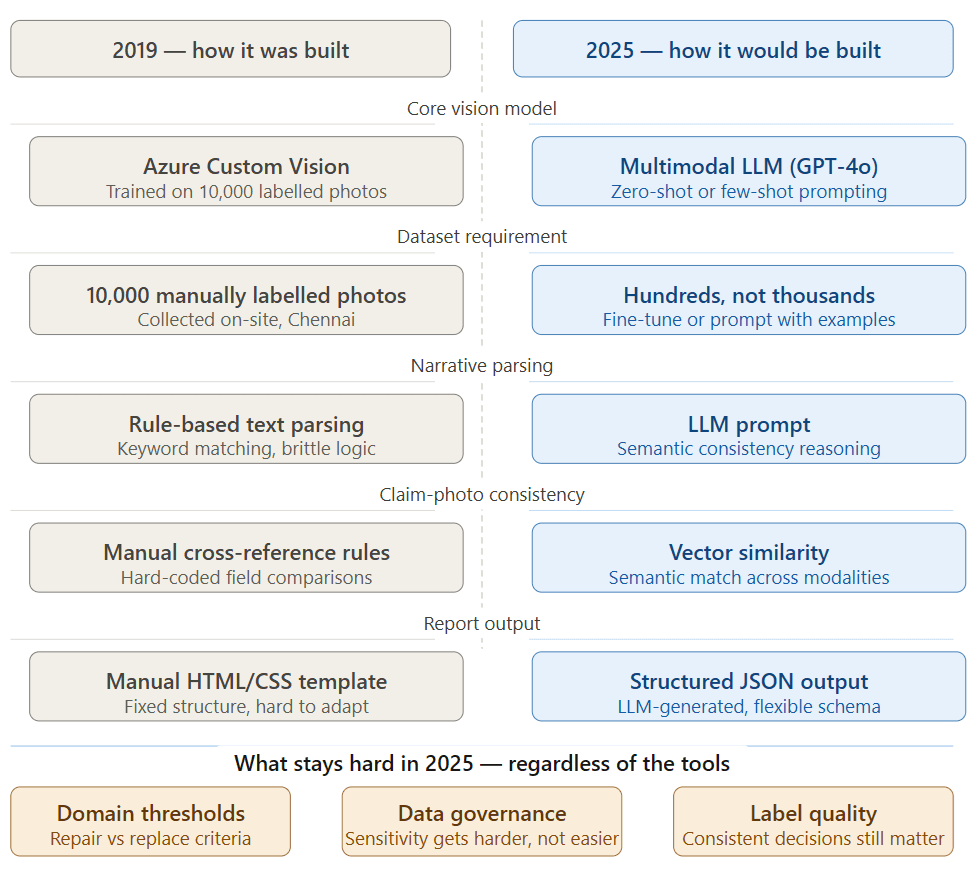
The dataset construction problem largely disappears. A multimodal foundation model can identify vehicle components and assess damage from photos without domain-specific fine-tuning. What would still require careful work is the business logic layer the repair/replace thresholds, the narrative cross-referencing criteria, the fraud signal definitions. The AI has become easier. The domain knowledge has not.
The geo-validation and narrative cross-referencing layers would become much more sophisticated with modern LLMs. Instead of rule-based narrative parsing, you could use a language model to reason about consistency between the claim story and the visual evidence catching subtler contradictions that a rule-based system would miss.
The training data problem, however, taught something that remains true regardless of the technology: the quality of your domain-specific labelling matters more than the sophistication of your model. A well-labelled, carefully constructed dataset with 10,000 examples will outperform a carelessly labelled dataset of 100,000. That lesson does not expire.
Key Takeaways
On building AI before it was easy: Doing hard things before the tools make them easy builds a depth of understanding that persists. Having constructed a custom vision model from a self-collected dataset in 2019, I understand multimodal AI at a level that goes beyond prompt engineering.
On fraud detection: The most effective fraud signals are often the simplest. Geo-tagging photo location against claimed incident location is not sophisticated AI, it is a metadata check. But it catches real fraud that sophisticated models miss entirely.
On POC outcomes: A successful POC that converts into an internal build is not a failed sales engagement. It is a proof that the solution worked well enough to be worth owning. Treat it accordingly.
On data sensitivity in insurance: The closer your AI system gets to financially sensitive operational decisions repair costs, replacement thresholds, adjuster benchmarks the more carefully you need to design the data governance model from day one. Not as an afterthought when the client raises it.